freebuf
freebuf最近抽空回顾了下java的序列化和反序列化,觉得之前了解的很浅显,索性对底层代码做了些分析。看了些师傅的文章,把笔记整理了下。个人觉得还可以。
序列化与反序列化
java序列化指的是将java对象转化为字节序列的过程。
java反序列化指字节序列恢复到java对象。
基础知识
计算机内存最小单位为一个二进制位,即 0或1。
我们把这个二进制位称为一个bit(比特)位。
一个字节(byte)有八个比特位,即 byte = 8*bit。
如果八个bit位都为1,即这个字节最大为 FF = 1111 1111。
一个字(word)是两个byte,即 word = 2 byte = 16 bit,
则一个字最大为 FFFF。
doubleword 双字,是两个word ,即四个byte,32*bit,
一个doubleword为FFFF FFFF。
一般情况下使用最多的是字节,字节相当于人民币的元一样,虽然不是最低的,但却是最常用的。
一串字符在内存中一般是以ascii编码形式存在,不同编码占用子节长度不同
一个ascii码的占用一个字节。
unicode码占用一个字(两个字节)。
utf-8 是我们国内常用的是针对unicode码的一种可变编码方式。
ascii


字节序
当一串数据太大的时候,一个字节放不下,就需要使用多个字节。
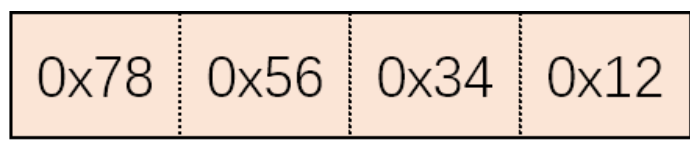
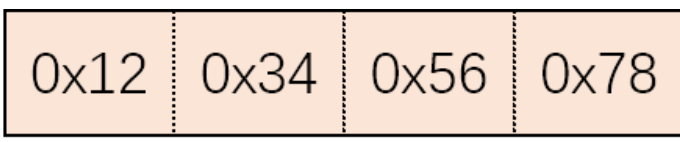
比如0x12345678就需要四个字节。
而现在就有了两种存放方式,
我们称这两种为 小端序和大端序。
小端序从屁股开始,大端序从头开始。
小端序
大端序
各家架构不同,使用的大小端序不同,无需纠结。
但是后来计算机网络通信出来了,大家如果有不同的话会导致混乱。
tcp/ip协议出来之后就规定网络通信必须使用大端序。
以上就是字节序的基本知识。
序列化与反序列化
序列化:
对象序列化的最主要的用处就是在传递和保存对象的时候,保证对象的完整性和可传递性。序列化是把对象转换成有序字节流,以便在网络上传输或者保存在本地文件中。序列化后的字节流保存了Java对象的状态以及相关的描述信息。序列化机制的核心作用就是对象状态的保存与重建。
反序列化:
客户端从文件中或网络上获得序列化后的对象字节流后,根据字节流中所保存的对象状态及描述信息,通过反序列化重建对象。
序列化就是把实体对象状态按照一定的格式写入到有序字节流,反序列化就是从有序字节流重建对象,恢复对象状态。
上面的简单点说,进程间通信可以将图片,视频,音频等信息用二进制方式传输。但是进程间的对象却不能这么搞。
比如我创建了一个User u1 = new User(1,”a”,100);
我要将它传给另一个软件(进程),
进程间的对象想要传输就需要序列化和反序列化。
序列化为二进制数据,可以永久存在硬盘里,也可以进行网络传输。
实现java序列化和反序列化
下面嫌太长了可以直接看例子。
JDK类库中序列化和反序列化API
java.io.ObjectOutputStream:
表示对象输出流;
它的writeObject(Object obj)方法可以对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中;
java.io.ObjectInputStream:
表示对象输入流;它的readObject()方法源输入流中读取字节序列,再把它们反序列化成为一个对象,并将其返回;
实现序列化的要求
只有实现了Serializable或Externalizable接口的类的对象才能被序列化,否则抛出异常!
实现Java对象序列化与反序列化的方法
若User类仅仅实现了Serializable接口,则可以按照以下方式进行序列化和反序列化:
ObjectOutputStream采用默认的序列化方式,对User对象的非transient的实例变量进行序列化。
ObjcetInputStream采用默认的反序列化方式,对对User对象的非transient的实例变量进行反序列化。
若User类仅仅实现了Serializable接口,并且还定义了readObject(ObjectInputStream in)和writeObject(ObjectOutputSteam out),则采用以下方式进行序列化与反序列化:
ObjectOutputStream调用User对象的writeObject(ObjectOutputStream out)的方法进行序列化。
ObjectInputStream会调用User对象的readObject(ObjectInputStream in)的方法进行反序列化。
若User类实现了Externalnalizable接口,且User类必须实现readExternal(ObjectInput in)和writeExternal(ObjectOutput out)方法,则按照以下方式进行序列化与反序列化:
ObjectOutputStream调用User对象的writeExternal(ObjectOutput out))的方法进行序列化。
ObjectInputStream会调用User对象的readExternal(ObjectInput in)的方法进行反序列化。
实例
user对象,使用的是上述第一种方式,所以User要实现Serializable。
import java.io.Serializable; public class User implements Serializable { int id; String name; String phone; #一些get set 构造参数,这里就不列举了} 序列化与反序列化
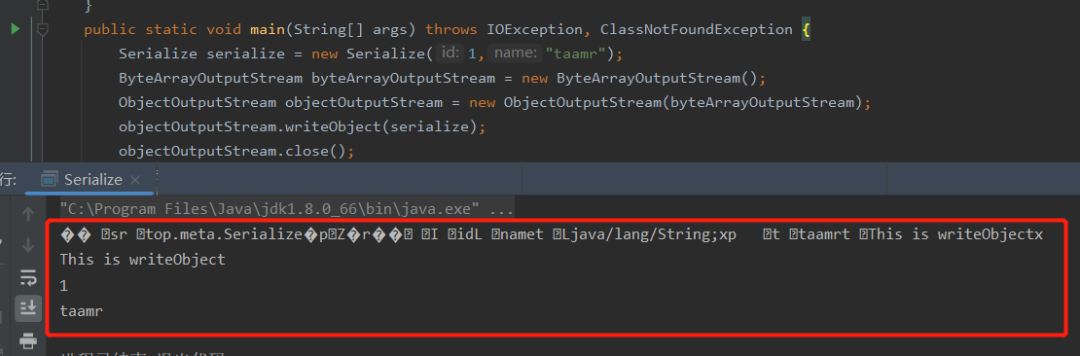
import java.io.*; public class userDemo { public static void main(String[] args) throws IOException, ClassNotFoundException { //创建对象 User u1 = new User(1,"AAAAAAA","110"); //被序列化的对象 User u2; //反序列化的对象 //序列化 getSerial(u1); //反序列化 u2 = backSerial(); System.out.println(u2.getName()); } //序列化 static void getSerial(User u1) throws IOException { FileOutputStream fos = new FileOutputStream("obj.out"); ObjectOutputStream oos = new ObjectOutputStream(fos); oos.writeObject(u1); oos.flush(); oos.close(); } //反序列化 static User backSerial() throws IOException, ClassNotFoundException { FileInputStream fis = new FileInputStream("obj.out"); ObjectInputStream ois = new ObjectInputStream(fis); User u1 = (User) ois.readObject(); return u1; }} 序列化底层分析
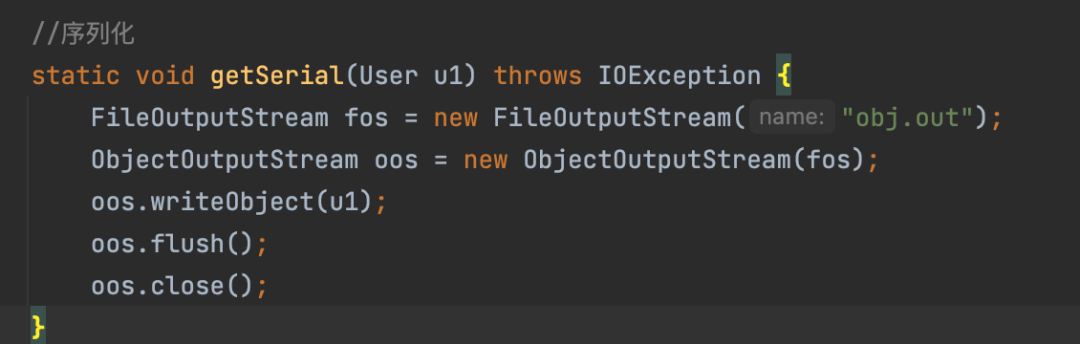
ObjdectOutputStream对象的初始化
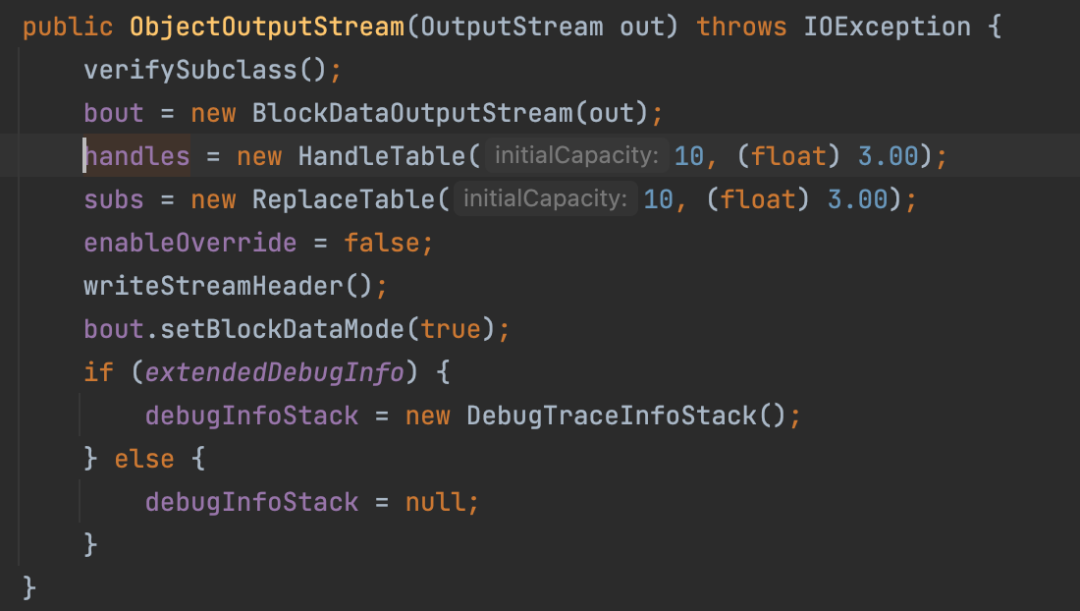
bout是数据输出流的底层
writeStreamHeader将文件头写入文件

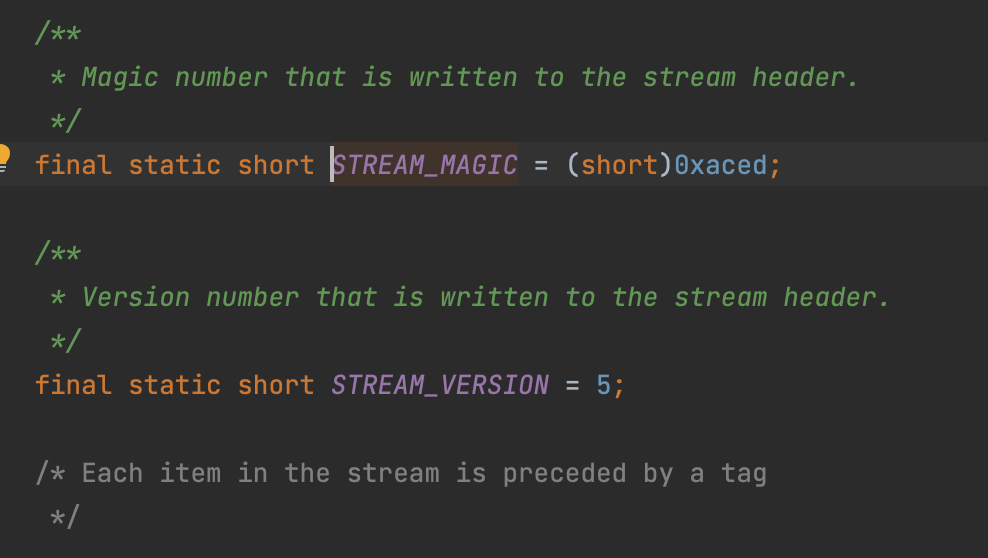
这里根据序列化的文件分析
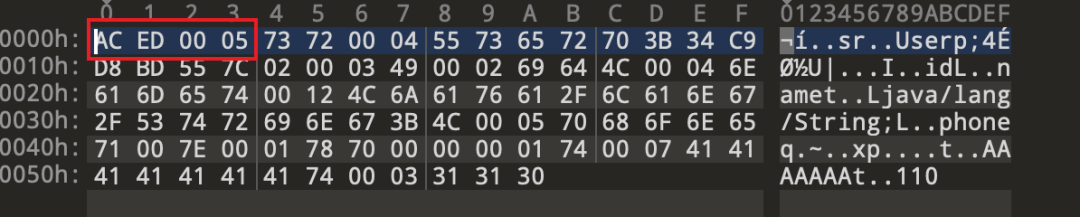
所以这里是写入文件头,表示声明使用序列化协议以及说明序列化版本
初始化完毕,文件存在且写入了文件头。
开始序列化写入文件
writeObject(u1);
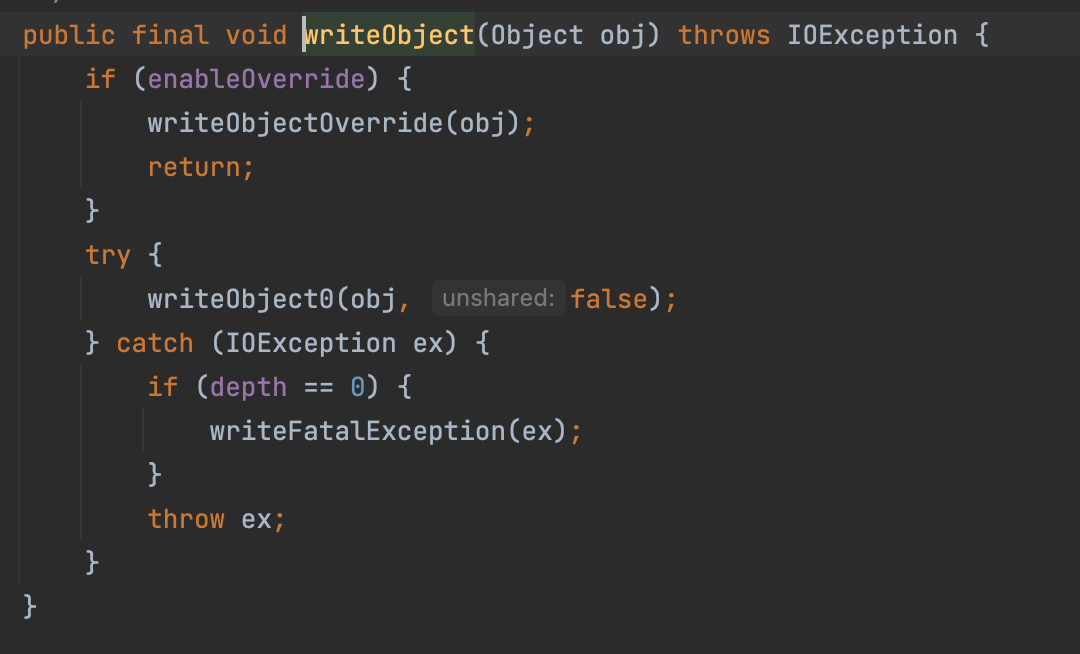
向下调用write0ject0();这个方法的内容比较长。重要点在意思是按照不同类型的方法去写入序列化数据,可以看上面实现Java对象序列化与反序列化的方法。
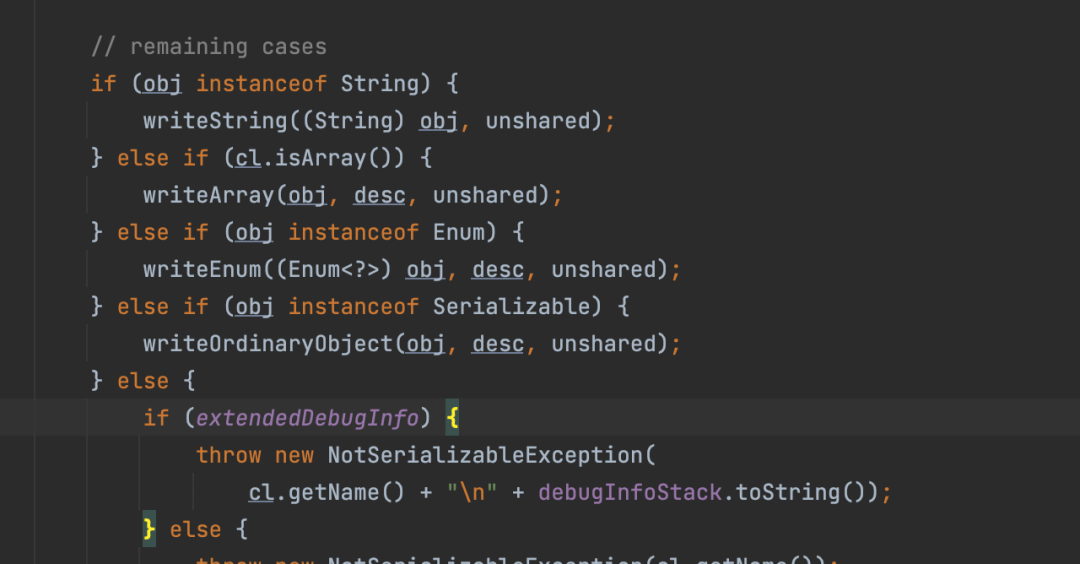
我们实例中实现了Serializable,所以执行writeOrdinaryObject方法。
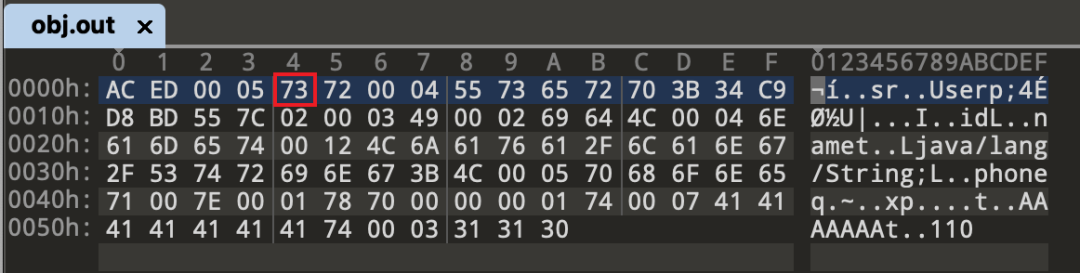
bout.writeByte(TC_OBJECT);

写入了0x73
调用 writeClassDesc(desc, false);跟进:
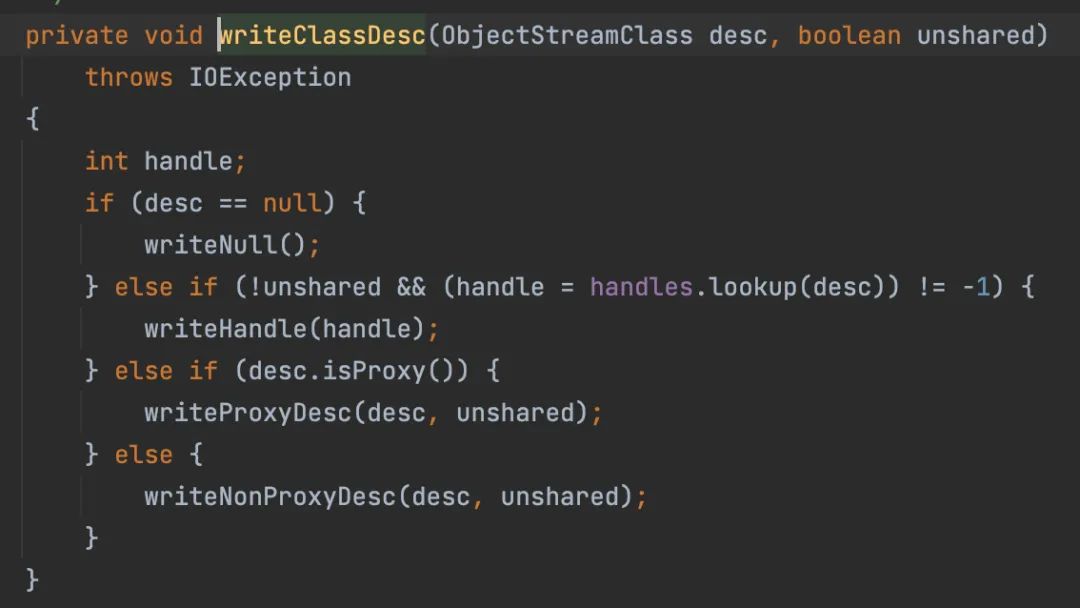
这里isProxy是判断类是否是动态代理模式。
具体可以自行了解,我也不清楚。因为我们实例的类不是动态代理,所以跟进writeNonProxyDesc();
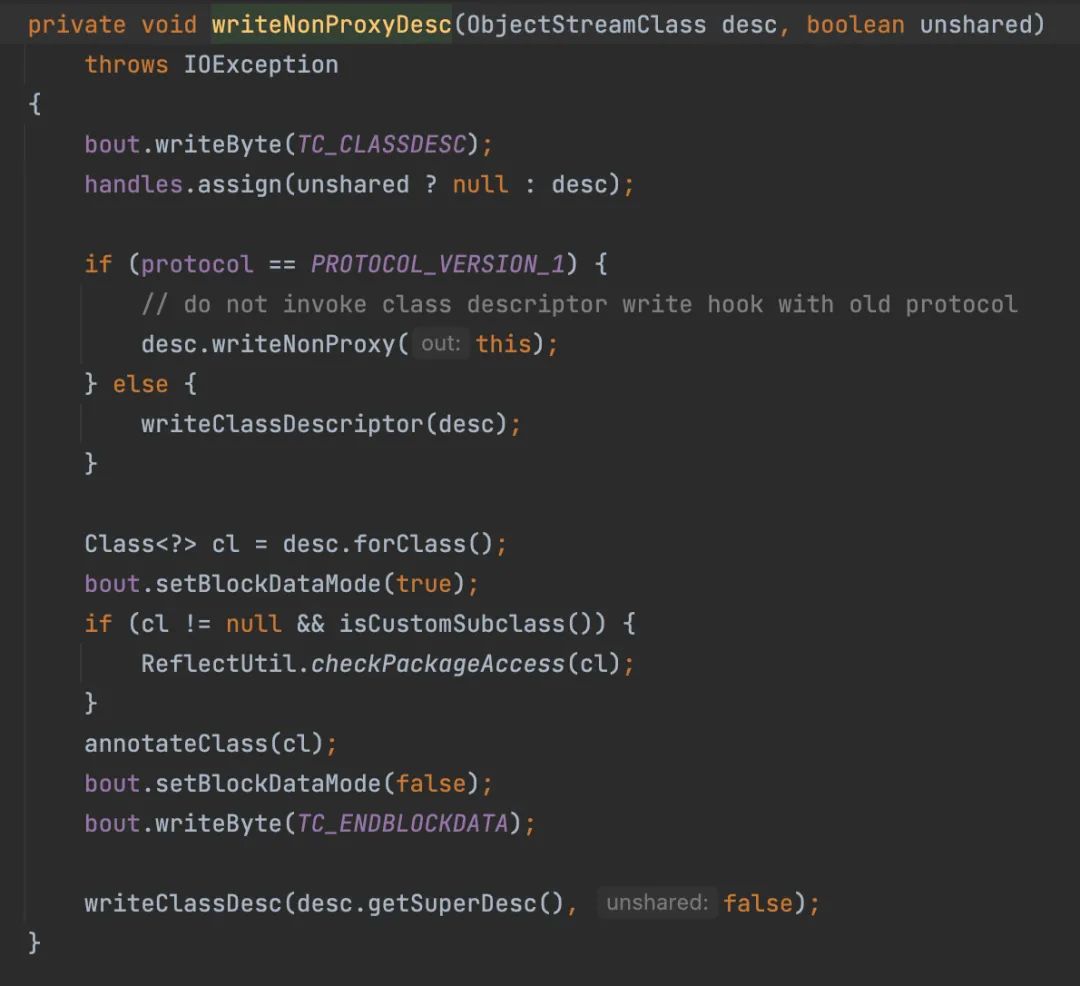
先写入了描述符号0x72
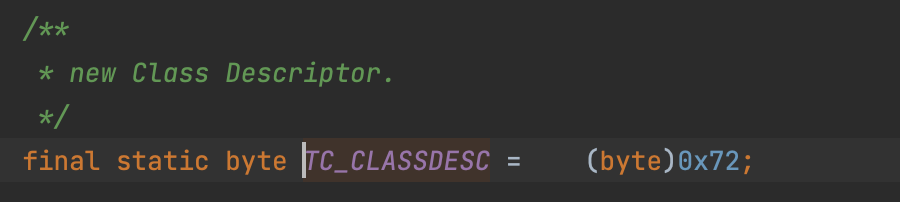

下面判断跟进两个参数一个为1,一个为2。跟进writeClassDescriptor(desc);
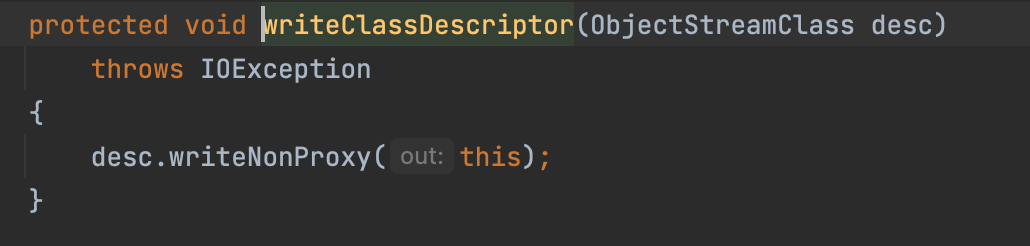
和true执行同一个方法:
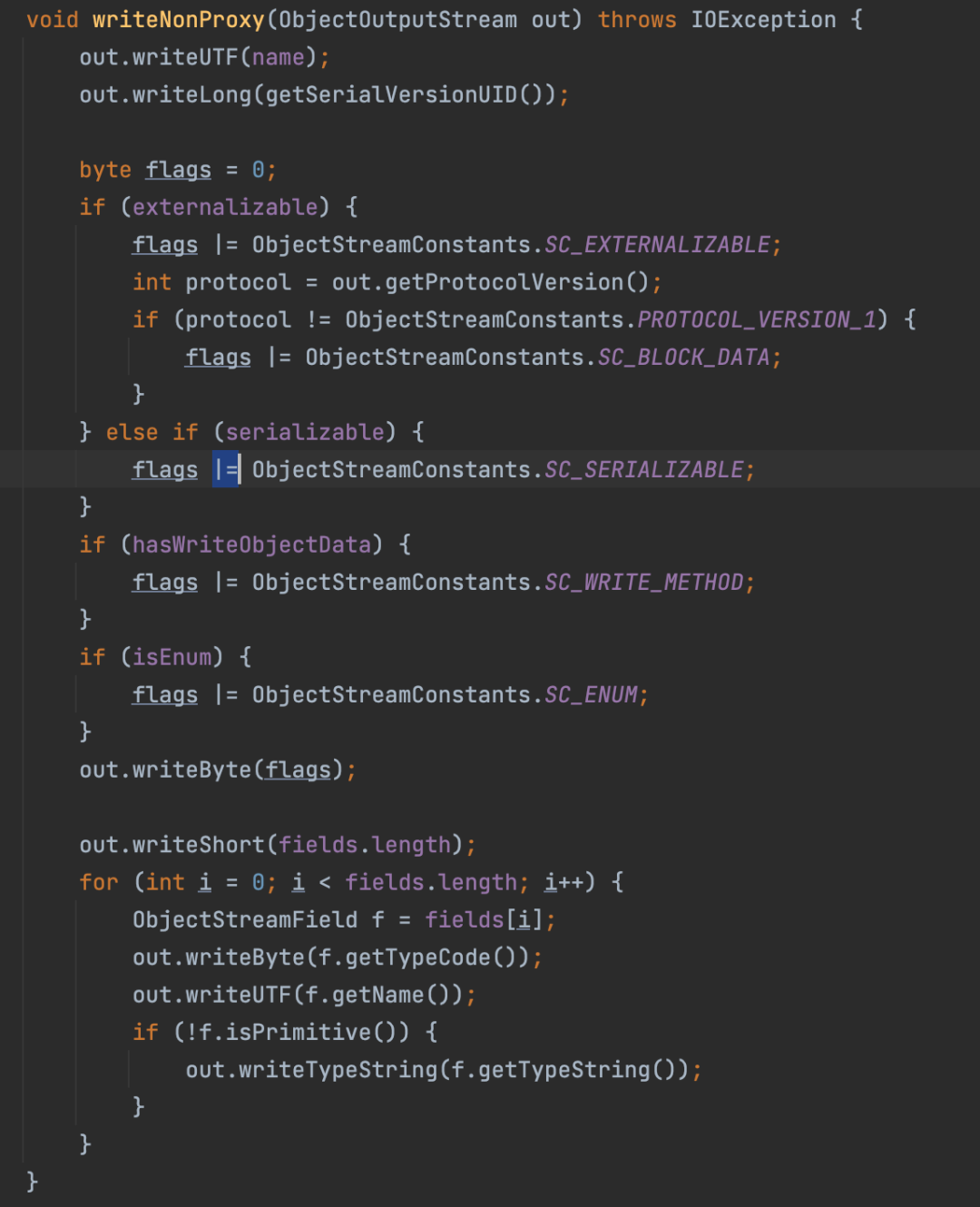
在开发中,我们经常会遇到要经过for循环来判断该循环体中是否包含或不包含某一元素,这个时候我们也常用一个boolean值来介入判断。而“|=”可以轻松的让我们完成实现。
boolean flag = false; 在一个循环体中,flag |= (c==e);如果一直不相等,则flag一直为false,一旦有一个相等则为true;
out.writeUTF(name);

写入类名
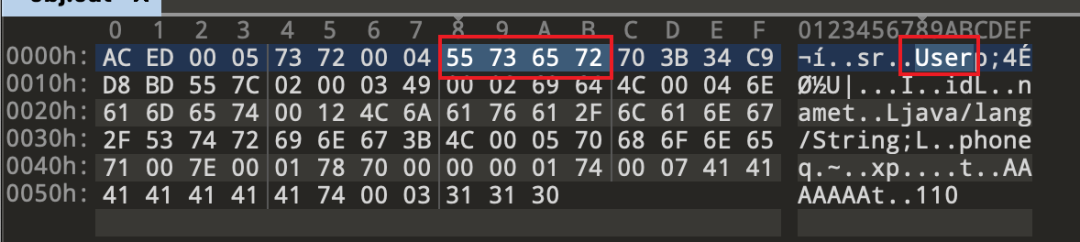
out.writeLong(getSerialVersionUID());
写入序列化uid
再往下一堆if判断接口的实现方式,将标志位写入
out.writeByte(flags);

我们使用serializable,所以应该写入0x02
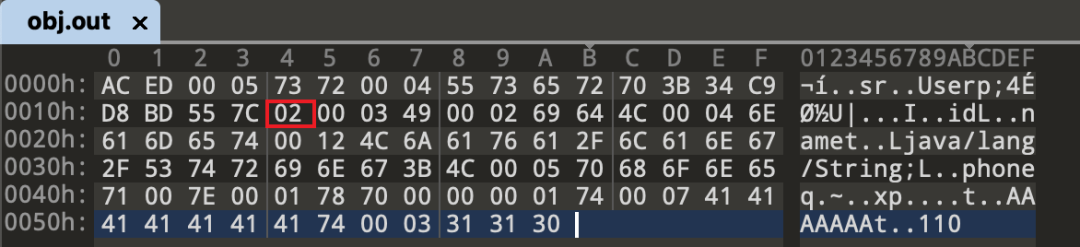
所以从0x000B - 0x0013 都是序列化uid
然后调用writeShort写入两个字节的域长度(比如说有3个变量,就写入 00 03 )。
实例中有三个参数

接下来就是循环写入变量名和变量类型。
每轮循环:
writeByte写入一个字节的变量类型,writeUTF()写入变量名,判断是不是原始类型,即是不是对象。不是原始类型(基本类型)的话,就调用writeTypeString()。
这个writeTypeString(),如果是字符串,就会调用writeString()。而这个writeString()往往是这样写的,字符串长度(不是大小)小于两个字节,就先写入一个字节的TC_STRING(16进制 74),然后调用writeUTF(),写入一个signature,这好像跟jvm有关。
最后一般写的是类似下面这串74 00 12 4c 6a 61 76 61 2f 6c 61 6e 67 2f 53 74 72 69 6e 67 3b“翻译”过来就是,字符串类型,占18个字节长度,变量名是 Ljava/lang/string;
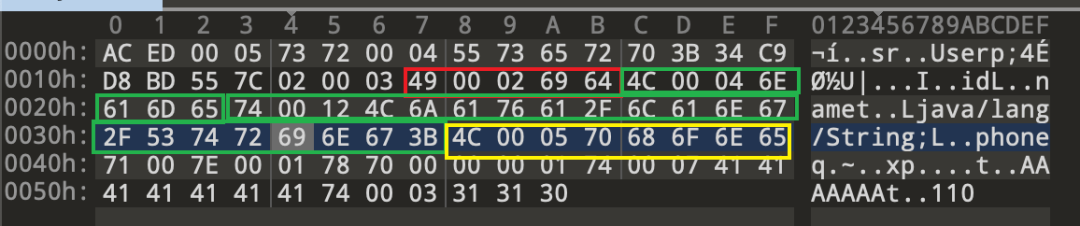 红色 id参数 int 类型
红色 id参数 int 类型
绿色 name 参数 string 因为 String是引用数据类型所以调用了writeTypeString() 写入了Ljava/lang/string;
黄色 phone 参数 string
这里第一次看有个疑问,phone参数也是string,但是他却没Ljava/lang/string;这一串,后边又增加一个string的参数,确定同一种引用数据类型只写入一次。
循环执行完,返回到writeNonProxyDesc方法,写入结束标志位0x78
bout.writeByte(TC_ENDBLOCKDATA);

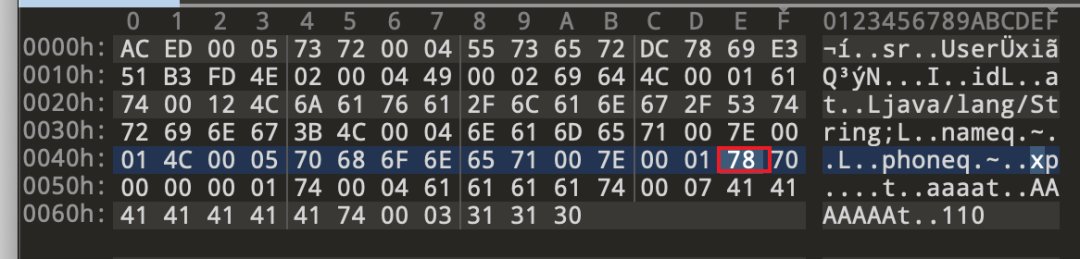
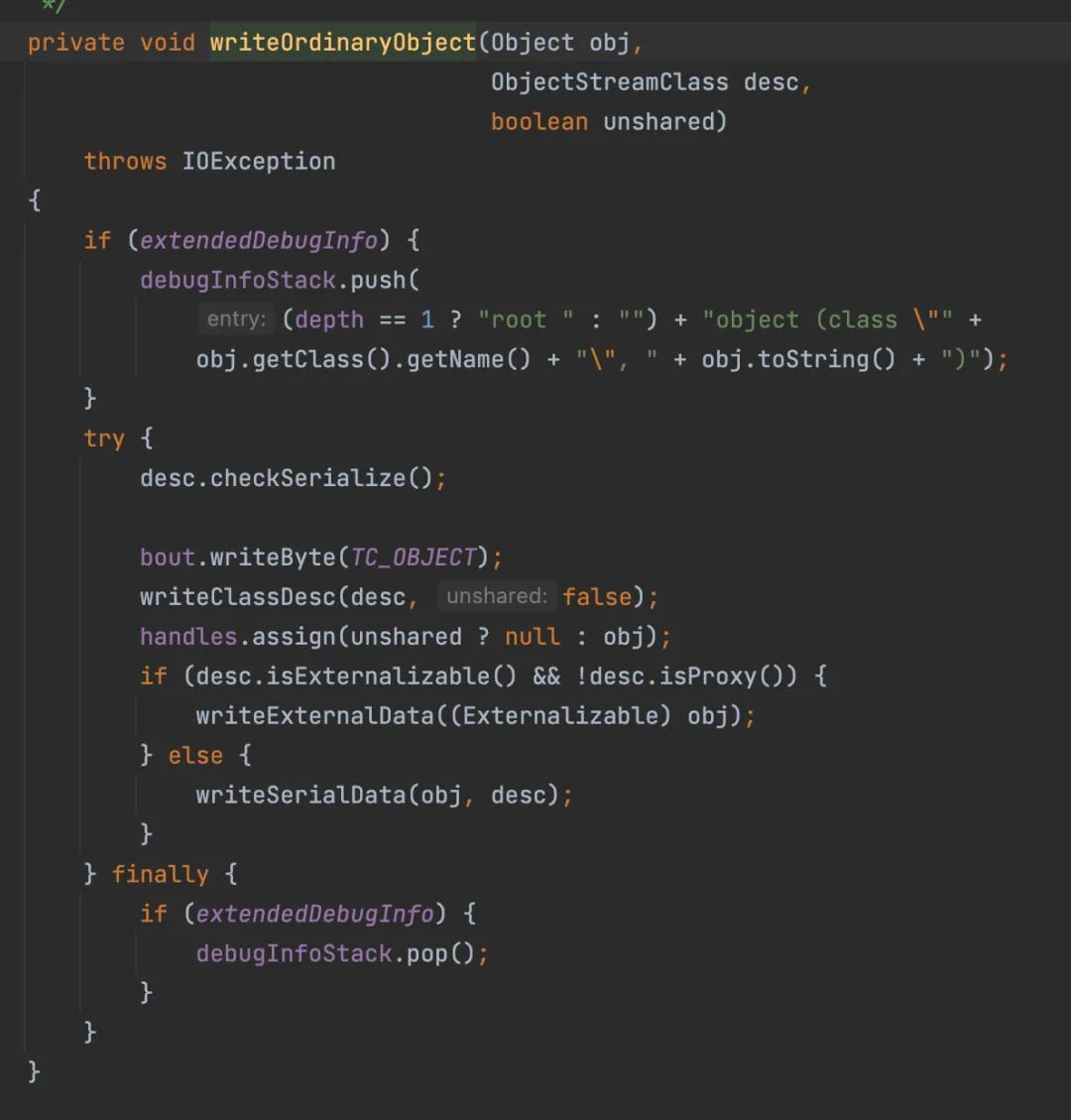
准备开始写入序列化数据,回到writeOrdinaryObject()方法,writeSerialData(obj, desc);方法来写入序列化数据
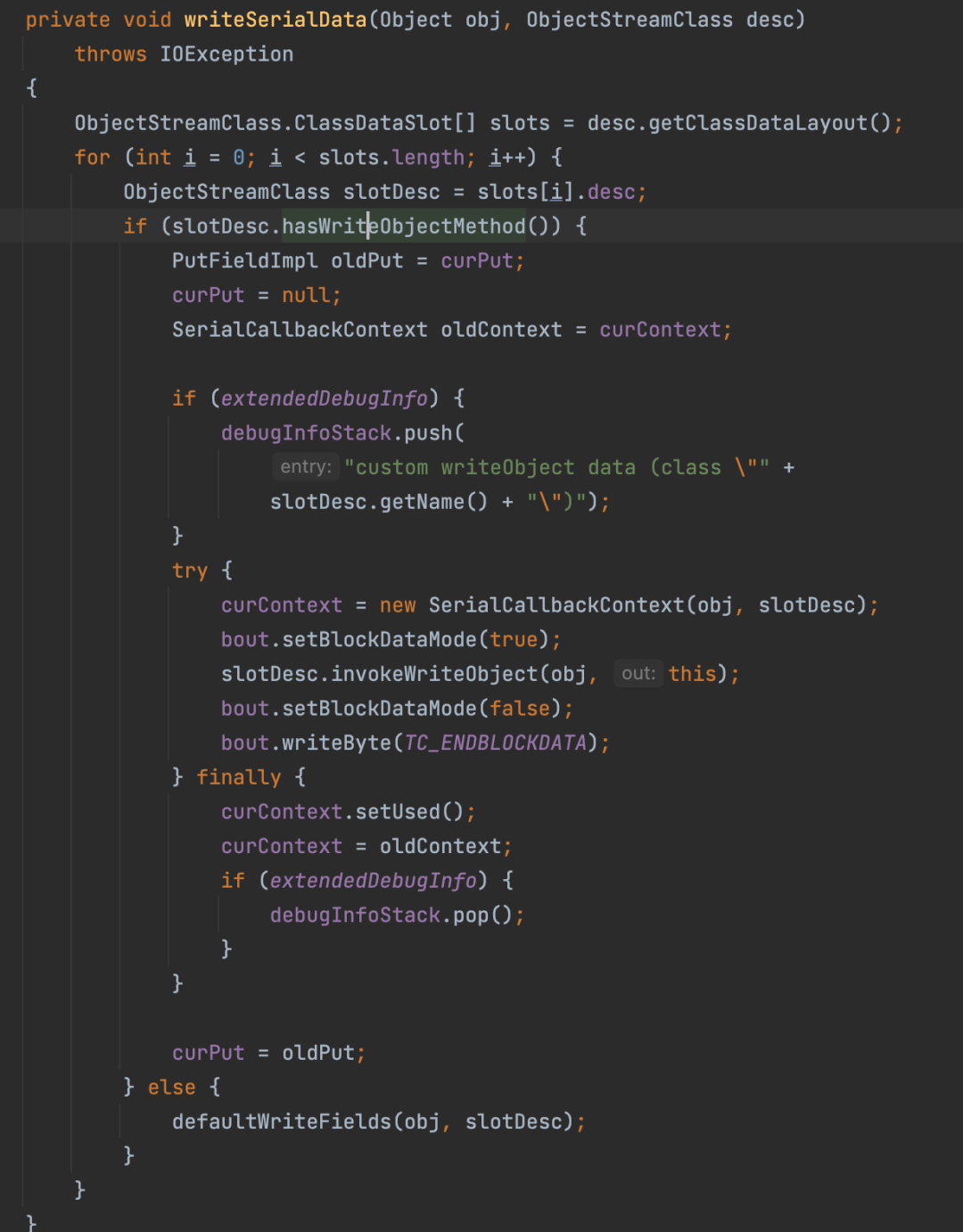
这里根据使用方式来判断,所以调用了 defaultWriteFields();
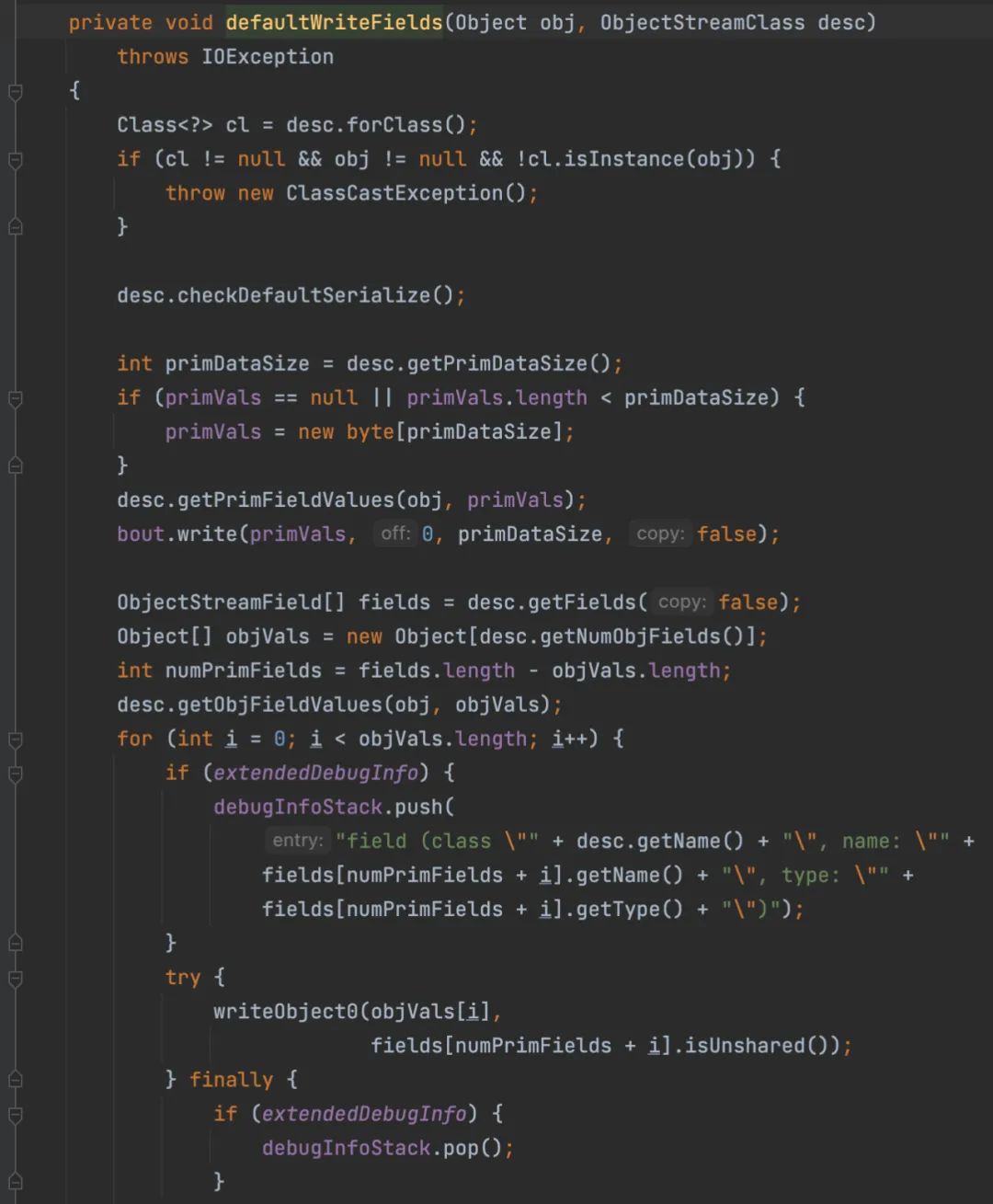
第二个if是判断是否为基本数据类型,是的话就会直接写入序列化数据,不是的话向下到for循环附近。获取变量数,然后循环调用writeObject0();写入
循环结束,直到所有运行完成,回到主函数。
反序列化就不写了,反反过来推一遍就成。
java反射机制
反射机制允许程序在运行期借助于Reflection API取得任何类的内部信息,并能直接操作任意类和对象的所有属性及方法。
要使用一个类,就要先把它加载到虚拟机中,在加载完类之后,堆内存的方法区中就产生了一个Class类型的对象(一个类只有一个class对象),这个对象就包含了完整的类的结构信息,我们可以通过这个对象看到类的结构,这个对象就像一面镜子,透过镜子可以看到类的结构,所以形象的称之为:反射。
实例:
import java.lang.reflect.Method; public class test { public static void main(String[] args) throws Exception { a1Class a1 = new a1Class(); //通过运行时的对象调用getClass(); Class c = a1.getClass(); try { //getMethod(方法名,参数类型) //getMethod第一个参数是方法名,第二个参数是该方法的参数类型 //因为存在同方法名不同参数这种情况,所以只有同时指定方法名和参数类型才能唯一确定一个方法 Method m1 = c.getMethod("print", int.class, int.class); //相当于r1.print(1, 2);方法的反射操作是用m1对象来进行方法调用 和r1.print调用的效果完全相同 //使用r1调用m1获得的对象所声明的公开方法即print,并将int类型的1,2作为参数传入 Object i = m1.invoke(a1,1,1); }catch (Exception e){ e.printStackTrace(); } } static class a1Class { public void print(int a, int b) { System.out.println(a + b); } }} 尝试简化上面的代码
创建另一个文件
public class testMiao { public static void maio(){ System.out.println("miao!"); }} 使用反射来执行miao();
public class test { public static void main(String[] args) throws Exception { try { Object s = Class.forName("testMiao").getMethod("maio").invoke(null); }catch (Exception e){ e.printStackTrace(); } }} 尝试添加参数简化
public class testMiao { public static void maio(String s){ System.out.println("miao!"+s); }} 反射
public class test { public static void main(String[] args) throws Exception { try { Class.forName("testMiao").getMethod("maio", String.class).invoke(Class.forName("testMiao"),"aaa"); }catch (Exception e){ e.printStackTrace(); } }} java执行命令
java中可以使用Runtime.getRuntime.exec();来执行系统命令
如:
 尝试使用反射来执行
尝试使用反射来执行
Class.forName("java.lang.Runtime").getMethod("exec", String.class).invoke("open /System/Applications/Calculator.app"); 这样会报错,报错的信息:是对象不是声明类的实例
说明exec只能是通过getRuntime来执行
import java.lang.reflect.Method; public class test { public static void main(String[] args) throws Exception { Object o = Class.forName("java.lang.Runtime").getMethod("getRuntime").invoke(null); Class.forName("java.lang.Runtime").getMethod("exec", String.class).invoke(o,"open /System/Applications/Calculator.app"); }} 这样会成功,原理跟随反射实例第一个实例来理解。
现在可以打开计算器,明白什么是序列与反序列化了。
关于cc1的链,之后再写,可以看bilibili 白日梦组长分析思路,我个人觉得他的思路是真的超级棒。
转载请注明来自网盾网络安全培训,本文标题:《java序列化与反序列化》
- 上一篇: 六方云勒索病毒解决方案重磅发布
- 下一篇: 欧洲刑警组织关闭世界最大黑客论坛之一RaidForums


![JDK9为何要将String的底层实现由char[]改成了byte[]?](https://img.nsg.cn/xxl/2022/05/f0d2fa7a-6972-4a7d-977b-d213f64aa5d3.png)